Manchmal gehen Kennwörter oder die Mensche die diese wussten verloren. Dann sollte ein gute Admin trotzdem den Zugriff auf die Hardware sicherstellen – manchmal auch mit „Gewalt“.
Leider hat DELL zwischenzeitlich beschlossen, eine ganze Menge KB-Artikel mit einer Paywall zu blockieren („Dieser Artikel ist berechtigungsbasiert. Suchen Sie einen anderen Artikel.“), so auch die „offiziellen“ Anleitungen 🤬
Wir hatten hier gleich mehrere (Dell) EMC DS-6505B zurückzusetzen. Daher hier die kompakte Anleitung für schnelle Admins. Ganz ohne Paywall.
Lösung
1. Boot-Console verbinden (Switch ist ausgeschaltet)
PC mit dem seriellen Anschluss (oder Adapter, FTDI FT232RL empfohlen) via Console-Kabel mit dem Serial-Port des Switches verbinden (das ist der port mit der „IOIO“ Beschriftung).
Mit PuTTY oder anderen Serial-Terminal Client den Port öffnen (9600baud, 8 data bits, 1 Stop bit, Parity none, Flow Control Xon/Xoff).
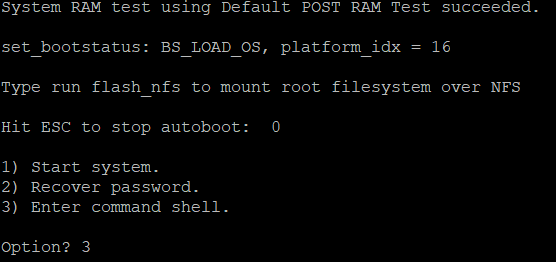
2. Switch einschalten, Recovery Command-Shell booten
Sofort nach dem Einschalten kann man den Boot-Prozess live bewundern. Ein paar Sekunden nach dem Start bei der Meldung „Hit ESC to stop autoboot:“ ESC drücken und mit „3“ die command shell starten.
3. Singele-User mode booten
Wenn es hier ein PROM-Kennwort gibt, einfach das Gerät noch einmal booten und selbiges Kennwort mit dem 2. Punkte „Recover password“ zurückesetzen.
An der boot-Shell kann man dem Bootloader jetzt den Parameter für den Single-User-Mode mitgeben und diesen auch gleich starten. Mit printenv sollte man vorher die Boot-Parameter anschauen (und am besten screenshotten). Möglicherweise werden die später noch gebraucht.
=> printenv
=> setenv OSLoadOptions "single"
=> boot4. Dateisystem(e) mounten
Natürlich mountet der Singleuser-Mode alle Laufwerke ReadOnly (RO), daher muss das vor den Änderungen natürlich umgestellt werden. Wir brauchen außerdem das Boot-Medium mit dem Flashfilesystem gemountet. Das bekommen wir aus der printenv Ausgabe der Variable OSRootPartition (der erste Wert, meistens /dev/hda2).
sh-2.04# mount -o remount,rw,noatime /
sh-2.04# mount /dev/hda2 /mnt
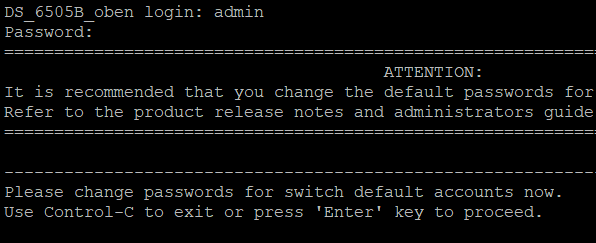
5. Kennwörter zurücksetzen
Jetzt kann man an der frisch gebooteten (Linux-) Shell die Kennwörter zurücksetzen und den Switch neu starten.
sh-2.04# /sbin/passwddefault
sh-2.04# reboot -f6. Neu starten und einloggen
Nach dem jetzt ungestörten Neustart kann sich der Benutzer admin wieder mit dem EMC/Brocade Default Passwort password einloggen.
Bonus: Factory Reset (Zurücksetzen auf Werkseinstellungen)
Wenn man schon mal dabei ist und der Switch „leer“ werden soll, kann man das Gerät jetzt noch direkt auf die Werkseinstellung zurücksetzen.
SWITCHNAME:admin> fosconfig --disable vf
SWITCHNAME:admin> switchcfgpersistentdisable
SWITCHNAME:admin> cfgDisable
[mit y bestätigen]
SWITCHNAME:admin> cfgClear
[mit y bestätigen]
SWITCHNAME:admin> cfgSave
[mit y bestätigen]
SWITCHNAME:admin> configDefault
[mit y bestätigen]
SWITCHNAME:admin> userconfig --change root -e yes
SWITCHNAME:admin> rootaccess --set consoleonly
SWITCHNAME:admin> cfgSave
[mit y bestätigen]
SWITCHNAME:admin> fastBootDas Default-Kennwort für den Standartmäßig abgeschalteten Benutzer root lautet übrigens fibranne.