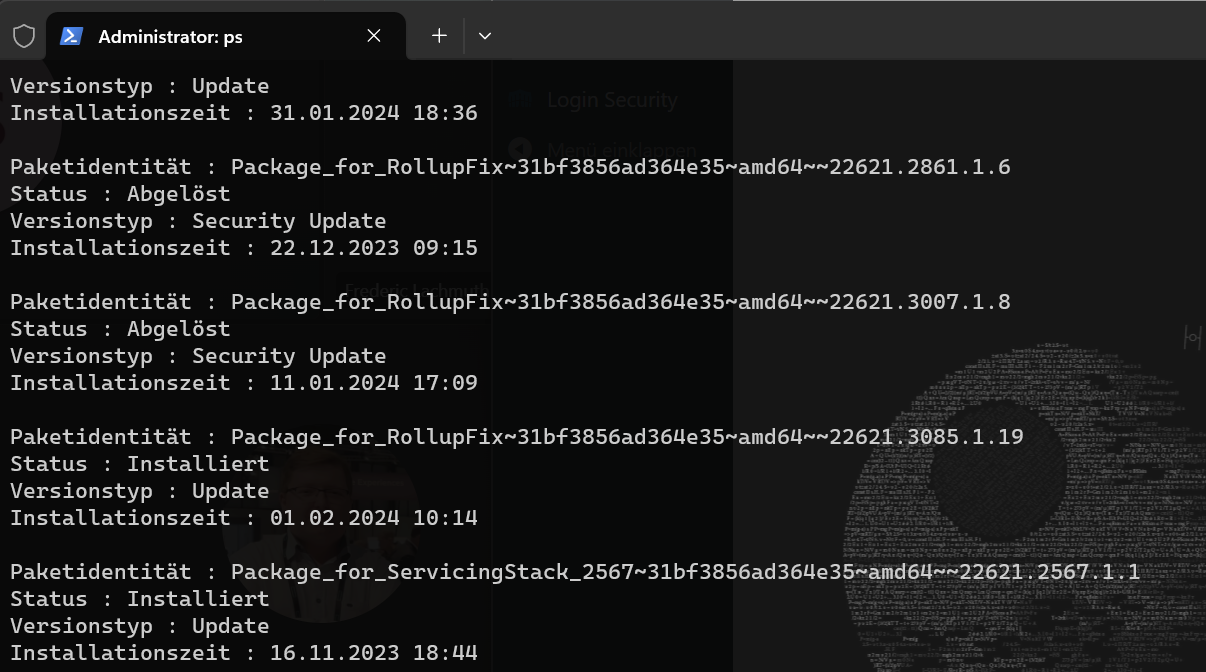
Unter Windows Server 2012R2 startet die PowerShell „auf einmal“ nicht mehr. Nach dem Start erscheint direkt „powershell funktioniert nicht mehr“ und der Konsolenhost schießt sich wieder.
Server 2012R2 ist zwar bekanntermaßen EOL und muss weg, aber manchmal braucht man für den Wechsel auf ein neues System nun ebenjene PowerShell.
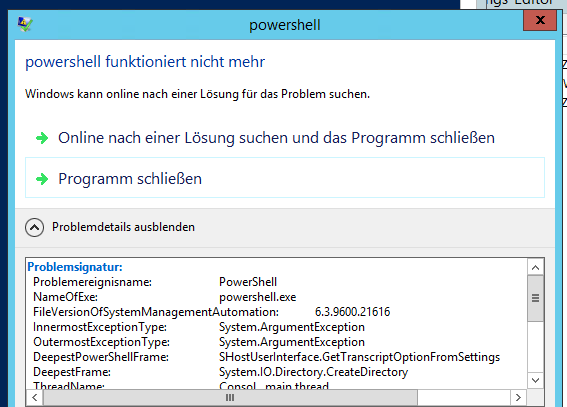
Die PowerShell stürzt ab mit diesem Fehler:
Problemsignatur:
Problemereignisname: PowerShell
NameOfExe: powershell.exe
FileVersionOfSystemManagementAutomation: 6.3.9600.21616
InnermostExceptionType:System.ArgumentException
OutermostExceptionType:System.ArgumentException
DeepestPowerShellFrame:SHostUserInterface.GetTranscriptOptionFromSettings
DeepestFrame:System.IO.Directory.CreateDirectory
ThreadName: Consol.. main thread
Betriebsystemversion: 6.3.9600.2.0.0.400.8
Gebietsschema-ID: 1031
Lesen Sie unsere Datenschutzbestimmungen online:
http://go.microsoft.com/fwlink/?linkid=280262
Wenn die Onlinedatenschutzbestimmungen nicht verfügbar sind, lesen Sie unsere Datenschutzbestimmungen offline:
C:\Windows\system32\de-DE\erofflps.txt
Lösung
In diesem Fall war es die Gruppenrichtlinie „PowerShell-Aufzeichnung aktivieren“ (Computer > Administrative Vorlagen > Windows-Komponenten/Windows PowerShell > PowerShell-Aufzeichnung aktivieren).
Die GPO setzt diesen Registry-Schlüssel:
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\PowerShell\Transcription]
"EnableTranscripting"="1"Server 2012R2 erwartet aber nicht nur diesen Key, sondern auch noch den Ausgabepfad als Zeichenkette (OutputDirectory). Bleibt die Zeichenkette leer, startet die PowerShell nicht mehr. Als Gegenprobe: Setzt man den Eintrag „EnableTranscripting“ auf „0“ funktioniert sofort wieder alles – bis die GPO den Eintrag wieder zurückändert.
Also gibt es als schnelle Lösung eine *.reg-Datei, die einfach dort einen Pfad (den es geben sollte!) hinzufügt:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\PowerShell\Transcription]
"OutputDirectory"="C:\\Windows\\Temp"
Solle die GPO beim nächsten gpupdate den Pfad wieder leeren, müsste man seine Richtlinie entsprechend anpassen. Oder (empfohlen) die Migration des 2012R2-Systems ASAP abschießen.