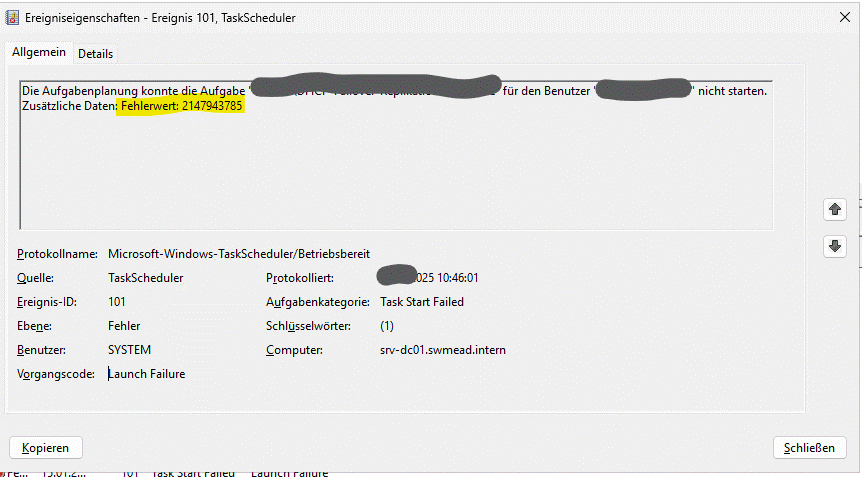
Vor allem auf neuen Windows Server 2025 DCs gibt es „Geplante Aufgaben“, die plötzlich nicht mehr funktionieren. In der Regel sind das Batch- oder PowerShell-Scripts. Die Fehlermeldung im Ereignisprotokoll lautet:
Die Aufgabenplanung konnte die Aufgabe „<JOB>“ für den Benutzer „<USER>“ nicht starten. Zusätzliche Daten: Fehlerwert: 2147943785
Lösung
Die neue Windows Server-Version respektiert nun (endlich?) standardmäßig die Richtlinie „Anmelden als Stapelverarbeitungsauftrag“. Der Fehler „2147943785“ sagt aus, dass der ausführende Benutzer nicht berechtigt ist, Stapelverarbeitungsaufträge auszuführen.
Der ausführende Benutzername muss in der passenden Richtlinie, entweder die „Lokale Sicherheitsrichtlinie“ oder in die passende Gruppenrichtlinie (empfohlen) aufgenommen sein.
Der Pfad der GPO findet sich hier:
Computerkonfiguration > Richtlinien > Windows-Einstellungen > Sicherheitseinstellungen > Lokale Richtlinie > Zuweisen von Benutzerrechten > „Anmelden als Stapelverarbeitungsauftrag“
Microsoft versucht ja bekanntlich, mit „Outlook (new)“ den guten, alten, abgehangenen und leidlich stabilen Outlook-Client abzulösen. Allerdings macht das neue JavaScript-Programm auch nach Jahren der Anpassungen immer noch einen äußerst unfertigen Eindruck, ganz abgesehen von der (naturgegebenen) zähen Langsamkeit der Weboberfläche. Wenn man dem Feedback-Hub zum neuen Outlook folgt, sind „zufriedene Anwender“ im maximal einstelligen Prozentbereich zu finden.
Ein überraschendes neues und ägerliches Phänomen ist, dass das „neue Outlook“ den Umgang mit langen Dateipfaden verlernt hat. Wenn man eine MSG/EML/PST Datei aus einem Pfad mit 1024 oder mehr Zeichen Länge öffnen möchte, erhält man diese irreführende (und offensichtlich nicht ans neue Design angepasst) Fehlermeldung:
Die Datei „XXX“ konnte leider nicht geöffnet werden. Sie sind nicht berechtigt, die Datei zu öffnen, oder die Datei ist leer.
Lösung
Inhaltlich ist das natürlich Unsinn, der Benutzer und praktisch alle anderen Windows-Apps (Notepad, Word, Excel, Outlook …) können die Datei problemlos öffnen. Nur das neue „Outlook (new)“ nicht. Verschiebt man die Datei an einen „kürzeren“ Ort, verschwindet das Problem aber sofort.
Microsoft Outlook, Excel und Word 365 aus den „Microsoft Apps for Enterrprise“ (früher Office Apps) stürzt seit Freitag in der Version Build 16.0.18324.20168 mit der „Programm reagiert nicht“ ab. Das passiert unter Windows Server 2016, beispielweise auf einem RDS (früher Terminalserver).
Die vorherige Version der „Microsoft Apps for Enterprise“ Office Version Build 16.0.18324.20168 funktioniert hingegen ohne Probleme.
Lösung
Lange Rede, kurzer Sinn: Ein aktuelles Microsoft Edge Update sorgt dafür, dass die Office-Apps unter Windows Server 2016 jetzt crashen. Schuld ist die neue Version der react-native-win32.dll.
Wir hoffen. Microsoft verklagt uns nicht, sondern repariert das defekte Update schnellstmöglich. Die Datei ist auch sicher echt, die Datei-Signatur ist intakt (SHA256: b15ea215d8cbb213c98a4d4ee45a2f42de07f5819a26394c40debae388882dae). Diese Lösung ist natürlich NICHT offiziell supported und wir warten auf ein repariertes Update von Microsoft.
⚠️ Wichtig: Die MP3-Endung der Datei ist aus Gründen da, aber das ist eine ganz normale ZIP-Datei. Einfach die MP3-Endung entfernen 😉
Update
Nach nur wenigen hundert Supportfällen, hat Microsoft das Problem anerkannt 👍
Die offizielle Meldung im Service-Portal: „Benutzerbeeinträchtigung: Microsoft 365-Anwendungen können auf Windows Server 2016 und 2019 Geräten unerwartet abstürzen.“
Während wir uns auf die Minderung konzentrieren, empfehlen wir betroffenen Kunden, ein Update zu erzwingen, um auf Version 2411 (Build 18227.20162) zurückzusetzen. Dies kann auch durch folgende Schritte erreicht werden:
Öffnen Sie die Eingabeaufforderung „als Administrator“
Führen Sie den folgenden Befehl aus: cd "C:\Program Files\Common Files\microsoft shared\ClickToRun"
Führen Sie den folgenden Befehl aus: OfficeC2RClient.exe /changesetting Channel=Broad
Führen Sie den folgenden Befehl aus: OfficeC2RClient.exe /update user
Ursache: Ein kürzliches Office-Update, das das React Native-Framework integriert, um bestimmte Funktionen in Microsoft 365-Anwendungen zu unterstützen, hat ein Problem eingeführt, das zu dieser Beeinträchtigung führt.
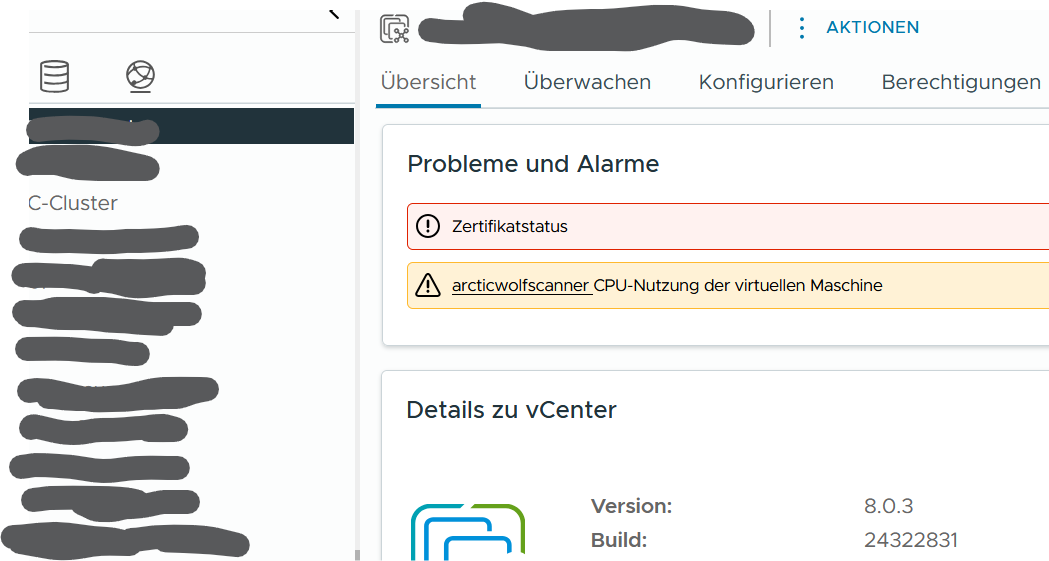
Manchmal begrüßt das vCenter den Admin mit einer eher rätselhaften „Zertifikatsstatus“ Fehlermeldung im vCenter UI. In diesem speziellen Fall war eine alte rootCA, die durch die Jahre der Datenmigration irgendwie noch vorhanden war. Es ist auch gar nicht so einfach, diese endlich loszuwerden.
Lösung
Zuerst muss man das betroffene Zertifikat finden. Es wäre natürlich viel zu hilfreich, wenn das UI das direkt anzeigen würde, daher muss man etwas tiefer gehen.
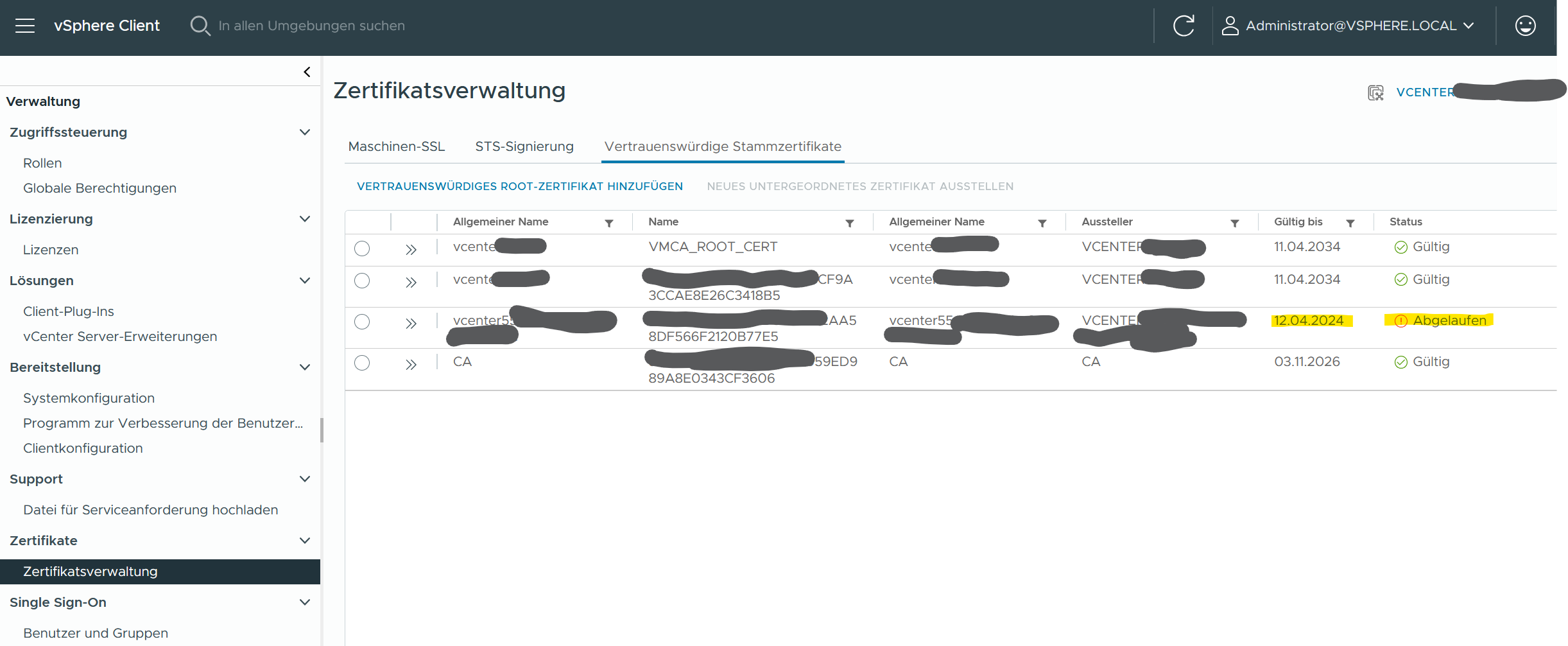
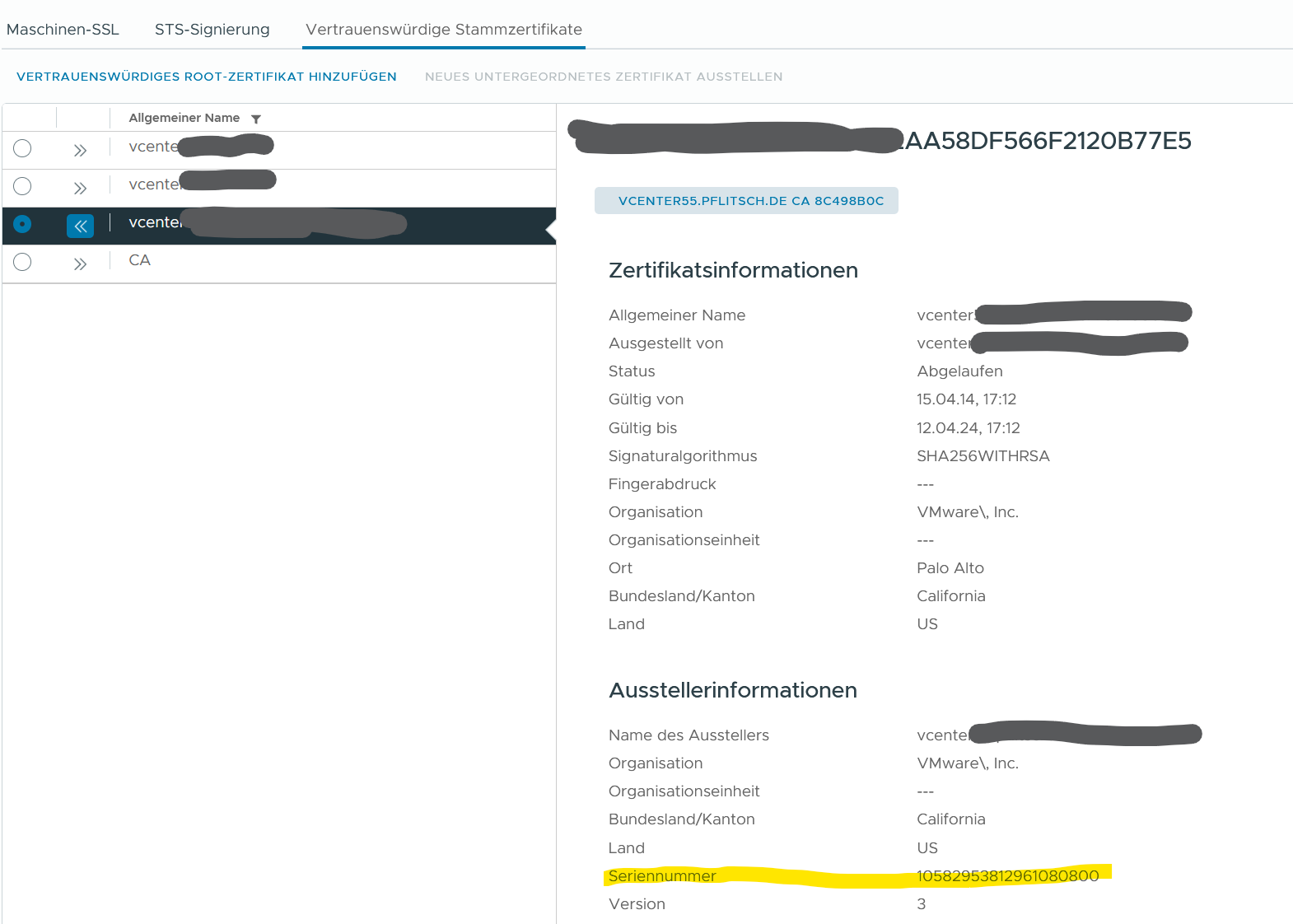
Die erste Anlaufstelle dazu ist der Zertifikatsmanager im vCenter unter Einstellungen > Verwaltung > Zertifikatsverwaltung. In diesem Fall hatten wir Glück, das abgelaufene „Vertrauenswürdige Stammzertifizierungsstellen“ Zertifikat war in der Liste enthalten. Das ist aber nicht immer der Fall, davon nicht entmutigen lassen.
Sollte das nicht funktionieren, kann man sich alle Zertifikate des vCenter Stores mit diesem Einzeiler an der Shell anzeigen lassen:
for i in $(/usr/lib/vmware-vmafd/bin/vecs-cli store list); do echo STORE $i; /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store $i --text | egrep "Alias|Not After"; done
Im zweiten Schritt holen wir uns die (dezimale) Seriennummer des Zertifikates. Die UI zeigt die Nummer an, wenn man das betroffene Zertifikat auseinanderfaltet. Selbige Seriennummer rechnen wir schnell in hexadezimal um, weil alle anderen Tools die Seriennummer nur als hex-Wert angeben (*seufz*).
Also in diesem Fall:
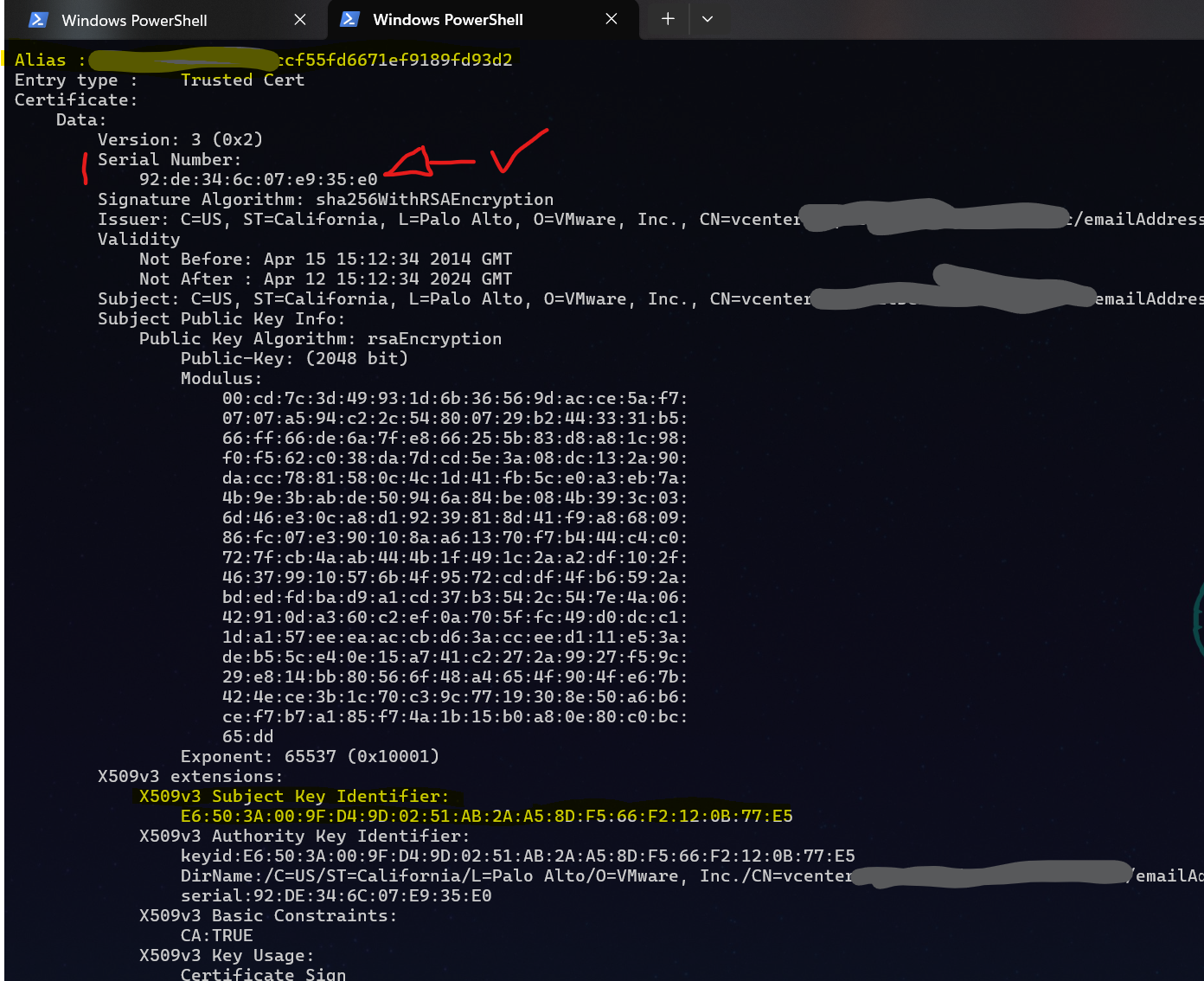
10582953812961080800 = 92:DE:34:6C:07:E9:35:E0
Mit der Seriennummer bewaffnet, können wir uns an der Shell die „echten“ Zertifikatsdetails heraussuchen. Die Liste der Zertifikate bekommt man mit („q“ um less zu beenden):
/usr/lib/vmware-vmafd/bin/vecs-cli entry list --store TRUSTED_ROOTS --text | less
ℹ️ Es können auch mehrere Zertifikate entfernt werden. Alle abgelaufenen (und nicht verwendeten) Zertifikate sollten sogar entfernt werden, um diese zertifikatsbezogenen Alarme zu entfernen.
Aus dieser Liste brauchen wir eigentlich nur Alias und den X509v3 Subject Key Identifier:
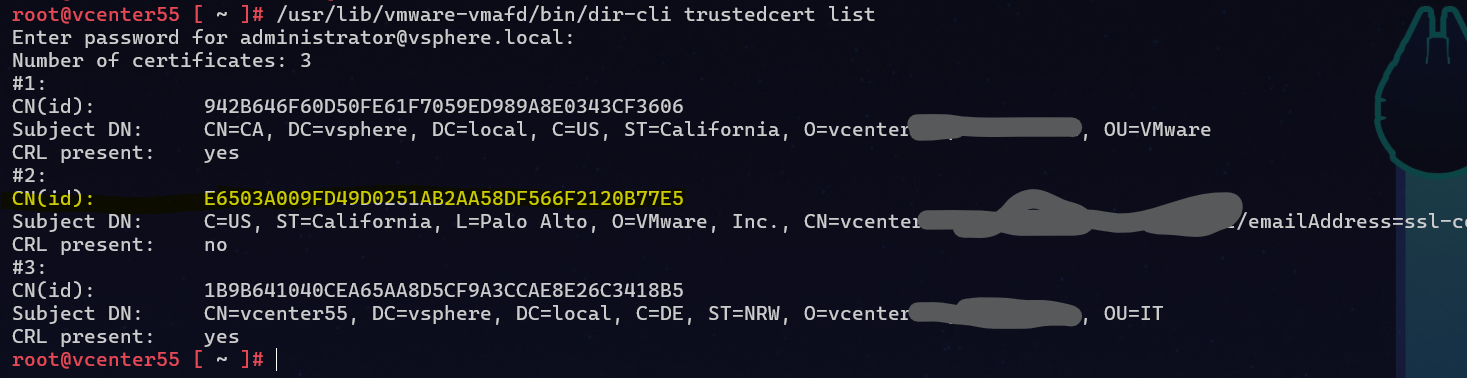
Jetzt brauchen wir von diesem Zertifikat wiederum den Thumbprint (vmware nennt das die „CN(id)“). Man nehme also nun den Fingerabdruck von dem CN, der abgelaufen gewesen ist. Die Fingerabdrücke listet man auf mit:
/usr/lib/vmware-vmafd/bin/dir-cli trustedcert list
Mit dem Thumbprint kann man nun endlich das Zertifikates exportieren und möglicherweise sogar ein Backup wegspeichern. Sicher ist sicher.
/usr/lib/vmware-vmafd/bin/dir-cli trustedcert get --id <THUMBPRINT> --login [email protected] --outcert /tmp/ABGELAUFENES-CERT.cer
Die Meldung „Certificate retrieved successfully“ bestätigt, dass das geklappt hat.
Wenn der Export vorliegt, kann man nun endlich das Zertifikat „Un-Publishen“:
Heute Morgen ist eine root-Partition auf einem Debian Server vollgelaufen. Da es unter Linux leider keine so komfortablen Werkzeuge zur Volumenverwaltung wie unter Windows gibt, hier die etwas umständliche, aber ebenso vollständige Anleitung in Schritten.
Die Platte in diesem Beispiel ist /dev/sda und die vergrößerte Version hat 80GiB.
/dev/sda
+--- /dev/sda1 --> / (Linux boot) bisher 30GiB
+--- /dev/sda2 --> Swap bisher 5iB
In diesem Fall gab s auf dem Boot-Volumen auch noch eine Swap-Partition, die in diesem Zuge kurzerhand auf ein zusätzliches Volumen verschoben wurde. Glücklicherweise ist beides im laufenden Betrieb möglich.
Lösung
Neue Disk-Größe einlesen
Nachdem die „Festplatte“ vergrößert wurde, erkennt Linux auch das nach einem rescan des SCSI-Busses. Je nach System mussm an das * durch das/die echte/n Gerät/e-Pfade ersetzen.
Dann kann man sich das aktuelle Partitionslayout und die größere Disk mit fdisk ansehen.
root@raumstation:~# fdisk /dev/sda
Welcome to fdisk (util-linux 2.36.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): pDisk /dev/sda: 80 GiB, 85899345920 bytes, 167772160 sectors
Disk model: Virtual disk
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x739a8a99
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 167772126 167770079 80G 83 Linux
Command (m for help):q
root@raumstation:~#
Swap-Partition abschalten und entfernen
Die Linux-Swap Partiton schaltet man ab mit swapoff. Der Parameter -a entfernt alle Swap-Partitionen des Kernels. Wenn man aktuell mehrere nutzt, muss man natürlich nur die „falsche“ außer Betrieb nehmen.
root@raumstation:~# swapoff -a
Dann kann man die Partitionen bis zur Volumengrenze löschen.
root@raumstation:~# fdisk /dev/sda
<d> für "delete"
<2> Nummer für die Partitionsnummer (fdisk schlägt die höchste vor)
<w> für "Write"
<q> für "Auit"Quit"
Linux Boot Partition vergrößern
Die einfachste Möglichkeit ist das growpart Werkzeug. Das ist sehr klein und schnell installiert.
Dann gibt es den Befehl, der die Partition automatisch so groß wie möglich macht:
growpart /dev/sda 1
Linux Dateisystem vergrößern
Wenn die Partition vergrößert wurde, muss nun das Dateisystem darüber informiert werden. Das geht zum Glück ebenso schnell.
resize2fs /dev/sda1
Neues Swap-Volumen anlegen und einbinden
In diesem Fall haben wir ein zusätzliches Swap-Volumen angebunden (/dev/sde), mit einem rescan (siehe oben) im System sichtbar gemacht und darauf mit fdisk eine Partition angelegt.
Bei der Größe der Swap-Partition halten wir uns gerne an die steinalte Admin-Weisheit „Immer die Hälfte vom Arbeitsspeicher, mindestens aber 4 und nie mehr als 32g.“
Wenn das geschehen ist, erstellt man das Swap-System mit mkswap …