Veeam B&R schreibt äußerst großzügige Logfiles, die die Fehlersuche in den allermeisten Fällen wesentlich vereinfachen. Das ist großartige – bitte bitte Veeam, ändert das niemals 😉
Früher(TM) war nicht nur alles besser, sondern man konnte über das Hilfe-Menü den Logfile-Ort schnell und komfortabel aufrufen; doch das war eine sinnvolle und hilfreiche Funktion und musste daher selbstverständlich ersatzlos gestrichen werden.
Naja, nicht ganz ersatzlos, denn dafür gibt es jetzt den freundlichen „Support-Assistenten“, der erst (wortwörtlich) Gigabyteweise Diag-Files zusammenkopiert, diese über alle CPU-Kerne verteilt einpackt und dem Informationensuchenden Admin schon nach einigen Minuten (!) ein wieder neu zu entpackendes .zip mit ALLEN logs darin präsentiert. In vielen Fällen eher sinnfrei, wenn Ihr mich fragt.
Lösung: Für das schnelle debuggen sind die Logfiles hier versteckt:
Windows Server XP/2003:
%allusersprofile%\Application Data\VeeamBackup
Windows Server 2008/2008R2/7:
%allusersprofile%\VeeamBackup
Windows Server 2026/2019/2022 und Windows 10: (thx Dezibel)
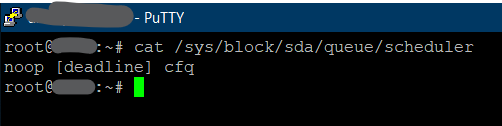
Im Linux Kernel sind seit 2.6.3irgendwas drei verschiedene I/O Scheduler enthalten. Der Klassiker NOOP, Deadline und der „moderne“ CFQ. So ein I/O Scheduler besitzt immer einen eigenen Algorithmus, um Lese- und Schreibrequests zu verarbeiten und an das Device für die physische Abarbeitung zu übergeben.
Mit „cat /sys/block/sda/queue/scheduler“ lässt sich der aktuelle Scheduler anzeigen
NOOP
Der NOOP-Scheduler ist ein vergleichsweise einfaches Ablaufmodell, das einfach alle I/O Requests in einer einzigen FIFO-Queue verwaltet und weitergibt. Es gibt in dieser Queue Request Merging, um und Seek-Times zu vermeiden, aber z.B. eine Sortierung findet nicht statt.
Deadline
Der Deadline-Scheduler ist gebaut um die „Starvation“ von Requests zu verhindern, also App-Timeouts durch *_WAIT zu vermeiden. Dazu werden in einer komplizierten Struktur Request mit einer Expiration Time versehen und in verschiedene Queues abgearbeitet. Dabei wird versucht, die Antwortzeiten für jeden Eintrag einzuhalten.
CFQ
Der „Completely fair queuing“ Scheduler ist zugleich der komplexeste, mächtigste und Standard-Scheduler des Kernels. Der Algorithmus versucht eine faire Aufteilung der vorhandenen I/Os auf alle Prozesse gleicher Priorität. Die „Fairness“ bezieht sich dabei auf die zeitliche Länge der Time-Slots und nicht auf die verwendete Bandbreite. Sequentielle Anfragen werden im gleichen Slot als immer eine höheren Durchsatz erzielen als ein Prozess mit random-Writes (welche durch Seek-times verlangsamt wird).
Dafür hat CFQ als einziger Scheduler die Möglichkeit, Prozesse in Prioritätsklassen einzuteilen. Von RT (RealTime) bis I (Idle) sind verschiedene abstufingen möglich.
Welchen nehme ich?
Wie immer in der IT gibt es hierauf keine eindeutige Antwort. In aller Regel ist der von der jeweligen Distribution ausgelieferte (und getestete) Modus eine gute Wahl.
In speziellen Szenarien, wie zum Beispiel extrem hoher random I/O Last bei vielen CPU-Kernen, kann die Umstellung auf einen anderen Scheduler aber etwas mehr Durchsatz (meint: mehr I/Ops) bewirken.
Wir empfehlen oft den Deadline Scheduler für Storages mit vielen SSDs, weil dieser nicht so viel Rechenzeit für das Mergen benötigt. SSDs sind oft schneller mit der Antwort fertig, als viele hunderte Merge-Operationen brauchen um abgesetzt zu werden. Noch schneller wäre NOOP, aber da ist die Gefahr groß, das ein Prozess mit exessiver I/O Nutzung alls anderen Operationen blockiert.
Die Änderung ist sofort aktiv, aber nicht persistent. Um die Umstellung über den nächsten Reboot zu retten, muss man dem Kernel den Startparameter elevator= mitgeben.
Unter Debian (beispielweise) passiert das in der /etc/default/grub in der Zeile
Bevor ich beim nächsten Fall schon wieder alles einzeln zusammensuche, hier eine kleine und schnelle Copypasta aus dem Admin-Alltag:
Sicherung einer WordPress-Instanz
Achtung: WordPress wird damit zwar vollständig eingepackt und die Datenbank gesichert, aber es gibt keine Fehlerbehandlung (Datei existiert bereits …) und auch keinen CSRF-Schutz. Die Kommandozeilen-Argumente werden un-escaped ausgeführt.
⚠ Das Backup landet automatisch in ~/priv wenn man den zweiten Parameter weglässt.
Syntax:
./wordpress-backup.sh /var/www/path-to-wordpress
Code:
#!/bin/bash
#
# SEHR einfaches WordPress-Backup
# Commandline-Argumente da?
if [ $# -eq 0 ]; then
echo "SYNTAX: wordpress-backup.sh <path-to-WordPress> <path-to-BackupFolder> [dbonly]"
exit 1
fi
wpdir=$1
bakdir=$2
# Backupverzeichnis angegeben?
if [ -z "$bakdir" ]; then
bakdir="~/priv"
fi
# Verzeichnisse da?
if [ ! -d $wpdir ]; then
echo "Directory $wpdir does not exist."
exit 1
fi
if [ ! -d $bakdir ]; then
echo "Directory $bakdir does not exist."
exit 1
fi
# Sinnvolle Dateinamen zusammenbauen
db_backup_name="wp-db-backup-"`date "+%Y%m%d"`".sql.gz"
wpfiles_backup_name="wp-files-backup-"`date "+%Y%m%d"`
# Zugangsdaten aus der config suchen
db_name=`grep DB_NAME $wpdir/wp-config.php | cut -d \' -f 4`
db_username=`grep DB_USER $wpdir/wp-config.php | cut -d \' -f 4`
db_password=`grep DB_PASSWORD $wpdir/wp-config.php | cut -d \' -f 4`
# MySQLdump, gzip
mysqldump --opt -u$db_username -p$db_password $db_name | gzip > $bakdir/$db_backup_name
# Nur wenn der dbonly Parameter nicht gesetzt ist
if [ ! "$3" = "dbonly" ]; then
# WordPress einpacken
tar -czvf $bakdir/$wpfiles_backup_name.tar.gz $wpdir
# Oder als zip:
#zip -r $bakdir/$wpfiles_backup_name $wpdir
fi
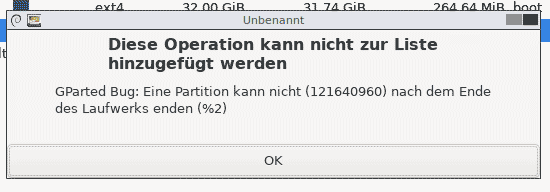
GParted beschwert sich bei der Anpasung von Partitionsgrößen: „GParted Bug: Eine Partition kann nicht (xxx) nach dem Ende des Laufwerks enden (%2)“
Die gleiche Meldung gibt es auch auf Englisch: „GParted Bug: A partition cannot end after the end of the device (%2)“
Das tritt beim resizing oder verschieben einer Partition auf, obwohl noch genug Platz da ist und das Ende des Laufwerks noch nicht erreich scheint.
Lösung
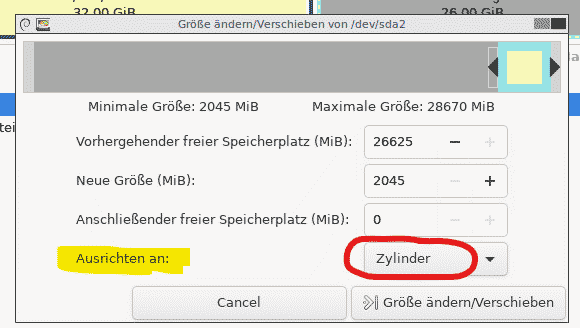
Der Fehler (Bug) liegt in der Berechnung der Partitionsgrenzen bei der Verwendung des Binärpräfixe gemäß IEC (MiB/KiB …). Man stelle den Dialog also einfach einfach auf „Zylinder“ (Cylinder) um, schon funktioniert die selbe Operation fehlerfrei.
Nach einem abgeschlossenen „dist-upgrade“ sind konfigurierte CUPS Drucker gerne mal deaktiviert („disabled“). Man kann einen Drucker nach dem anderen natürlich manuell einschalten („enable“), aber schöner wäre es die ganze Liste auf einmal zu aktivieren. Dafür gibt es das tool „cupsenable„.