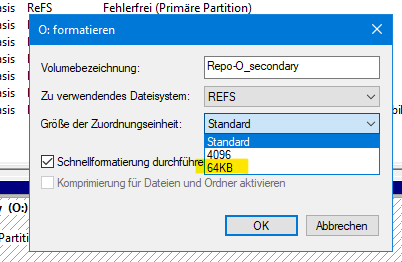
ReFS ab v3.1 unterstützt bekanntlich zwei verschiedene Clustergrößen: 4 KB und 64 KB. Welches nimmt man für ein B&R Repository?
tl;dr: 64KB für ReFS als Veeam-Repository
Aber warum?
Unter anderem Microsoft hat 2019 in einem Technet-Artikel einige Empfehlungen zur Clustergröße für ReFS und NTFS veröffentlicht. Die Standard-Clustergröße beider Dateisysteme ist 4K, was bis heute die Vorgabe ist, wenn man ein neues Volume formatiert. Der Artikel enthält aber auch eine detaillierte Erklärung, warum man eine bessere Performance mit 64K großen Zuordnungseinheiten erhält, wenn man große Dateien ließt oder schreibt.
64-KB-Cluster sind grundsätzlich immer dann sinnvoll, wenn man mit großen, sequentiellen E/A-Vorgängen (auf HDDs) arbeitet. Viel weniger Verwaltungsaufwand bei der Adressierung, mehr Payload und damit höherer Durchsatz bei deutlich weniger Last (etwa ein sechzehntel). Sicherungen und Wiederherstellungen erfolgen naturgemäß in aller Regel sequentiell, daher sind Veeam-Blöcke schon immer größer gewesen, nämlich 1Mbyte.
Insbesondere die „brutto“ Read/Write-Leistung unterscheidet sich erheblich, wenn dasselbe Volume auf derselben Hardware mit einer Clustergröße von 64 KB statt mit 4 KB formatiert wird. Eine bis zu vierfachen Steigerung der Netto-Geschwindigkeit von Merge-Vorgängen (Inkremental-Forever, Synthetic-Fulls …) ist üblich. Beide Vorgänge sind dank der Block-Cloning-API (ReFS-only!) immer noch erheblich schneller als „normales“ i/o, aber der Unterschied ist gewaltig. Die reine Backup-Schreibleistung hängt meist von der Quelle ab, daher fällt der gefühlte Unterschied hier ncht so groß aus.
Nachteile?
Ein Nachteil ist der zusätzliche Speicherplatzverbrauch. Dier beträgt, aus Erfahrung, etwa 5–10% der Dateigröße (nicht Volumengröße). Der Grund dafür ist, dass von Veeam erstellte Blöcke zunächst eine feste Größe von 1MB haben. In den allermeisten Veeam-Jobs ist aber standardmäßig die Komprimierung aktiv, die „im Durchschnitt“ die Größe nachträglich um etwa etwa 50% reduziert. Je nach Quelldaten fällt das natürlich leicht unterschiedlich aus, was in variabler „Verwendung“ von Cluster-„Rändern“ mündet.
Wir halten den Preis von <10% Speicherplatz für die Geschwindigkeits-Vervielfachung für hinnehmbar und empfehlen daher ebenfalls die 64KB Blockgröße.