Die Einrichtung des vCenter Servers mit dem Active Directory als Identitätsquelle ist etwas umständlich zu erledigen als unter 4.x/5, aber der Aufwand lohnt sich. Das SSO-Backend unter vSphere 5.5 ist praktisch komplett neu geschrieben und daher deutlich gradliniger als das SSO-Gebastel von früher. Leider ist dabei einiges an Adminfreundlichkeit auf der Strecke geblieben.
Ziel dieses Artikels: Ein vCenter Server soll gegen ein Active Directory („Windows Sitzungs-Anmeldedaten verwenden“) authentifizieren. Netzwerkdaten, DNS, Hostnamen und so weiter sind korrekt eingerichtet und der vCenter Server läuft soweit.
1. vCenter zum Active Directory hinzufügen
vCenter Verwaltungs-Weboberfläche (https://vcenter55:5480) öffnen.
- Als root anmelden
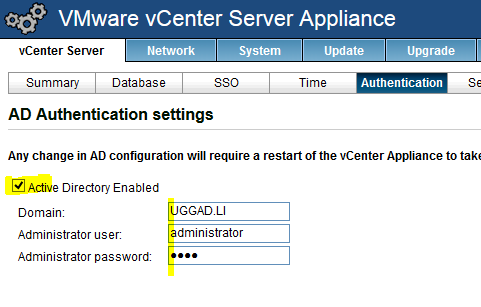
- Tab vCenter Server -> Authentication den Haken bei „Active Directory Enabled“ setzen und passende Domänenanmeldedaten eingeben
- „Save Config“
- Unter „SSO“ den Usernamen für den SSO-Login merken und ein Kennwort konfigurieren
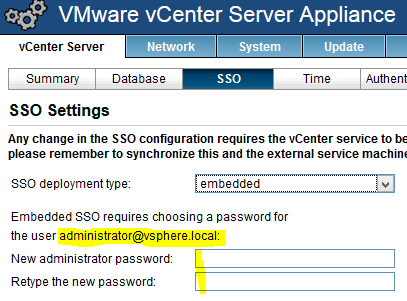
- vCenter Server neu starten: System -> Reboot
2. Identitäsquelle hinzufügen
- In den vSphere Webclient als der (oben gemerkte) SSO-Administrator einloggen (https://vcenter55.wittgastec.de:9443/vsphere-client)
- Verwaltung -> Konfiguration
- Oben links auf das grüne Plus, die Identitätsquelle hinzufügen und das Fenster ausfüllen
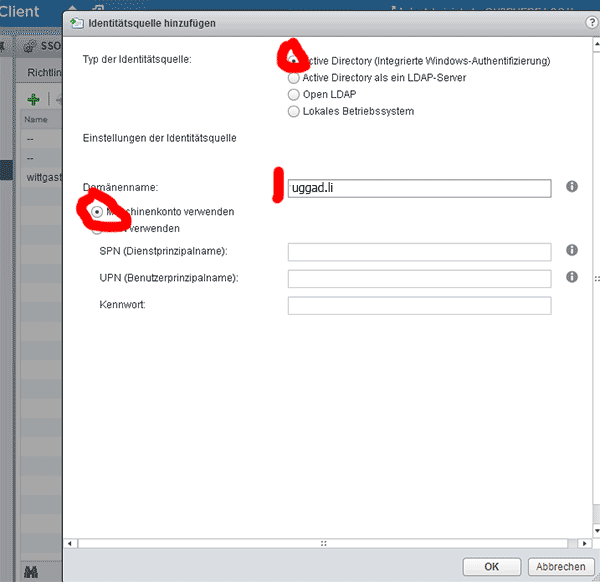
- Domäne auswählen und „Als Standarddomäne festlegen“
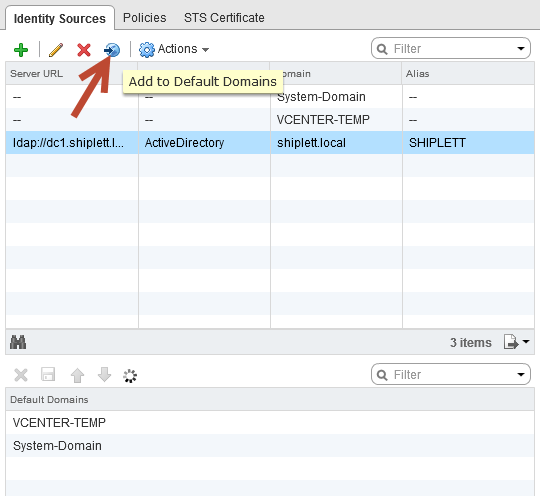
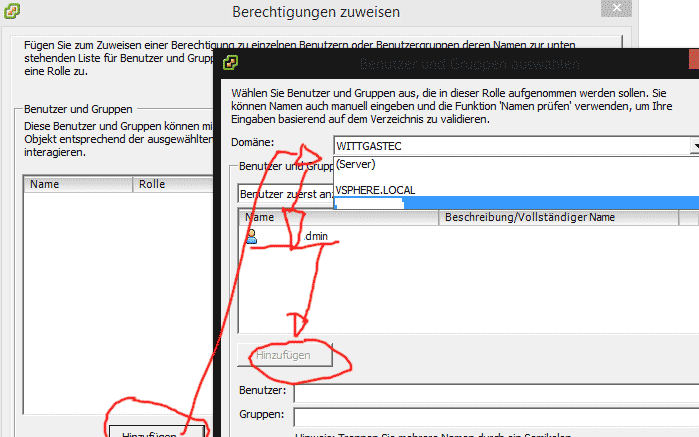
3. Rechte für Domänen-Benutzer oder Domänen-Gruppen hinzufügen
Der Einfachheit halber nutze ich jetzt den guten alten vSphere (C#-) Client. Flash ist für die Weboberfläche ja ein dermaßen üble Wahl, das ich soweit möglich beim Client leiben werde. Aus Abwärtskompatibilitätsgrünen kann man als Admin darauf ja eh nicht wirklich verzichten. Also Client auf und als root am vCenter anmelden.
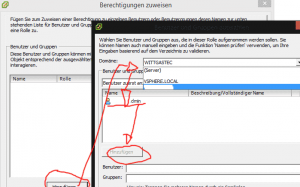
- Den vCenter Server auswählen -> Berechtigungen -> unten rechte MT und „Berechtigungen hinzufügen“
- Einen neuen Benutzer „Hinzufügen“ und in dem Hinzufügen-Fenster oben die Domäne auswählen
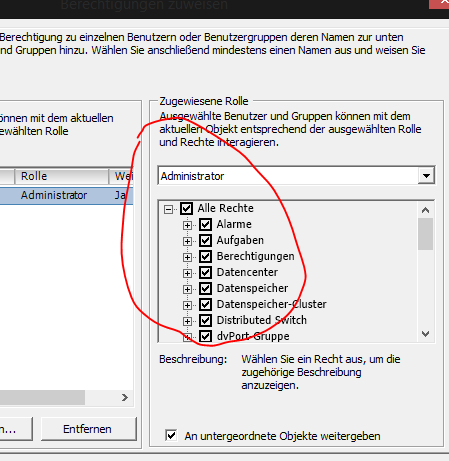
- Gewünschte Rechte vergeben
Schon fertig 🙂