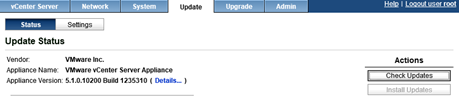
In der Weboberfläche (https://<vcenter-appliance>:5480/) ist das Update der Appliance schnell gestartet:
Leider schlägt das Update bei der Version 5.1 (Build 880472 und kleiner) gerne fehl. Das Update läuft in der Regel in paar Stunden lang (ich habe schon 4-5 Stunden gewartet), im Gegensatz zu den Aussagen von vmware (…“the update process halts for nearly an hour and the update status at Web UI shows as installing updates. However, eventually, the update completes successfully after an hour.“). Schuld ist ein Fehler ist der FIPS-Sicherheitsprüfung der SSL-Module
In der Regel ist das Update trotz langer Wartezeit irgendwann mit diesem Fehler in einem halbkaputten Zustand:
./etc/init.d/vami-sfcb: line 238: 7385 Aborted nohup /opt/vmware/share/vami/vami_sfcb_test > /dev/null 2>&1
./etc/init.d/vami-sfcb: line 238: 7398 Aborted nohup /opt/vmware/share/vami/vami_sfcb_test > /dev/null 2>&1.failed, restarting vami-sfcbd.
Shutting down vami-sfcbd: done.
Starting vami-sfcbd: done.
Checking vami-sfcbd status:/etc/init.d/vami-sfcb: line 238: 7513 Aborted nohup /opt/vmware/share/vami/vami_sfcb_test > /dev/null 2>&1
./etc/init.d/vami-sfcb: line 238: 7526 Aborted nohup /opt/vmware/share/vami/vami_sfcb_test > /dev/null 2>&1
./etc/init.d/vami-sfcb: line 238: 7539 Aborted nohup /opt/vmware/share/vami/vami_sfcb_test > /dev/null 2>&1
./etc/init.d/vami-sfcb: line 238: 7552 Aborted nohup /opt/vmware/share/vami/vami_sfcb_test > /dev/null 2>&1
Es hilft, VOR DEM UPDATE die SSL-Bibliotheken und Binaries auf den aktuellen Stand zu bringen und die FIPS-Hashes zu löschen. Das geht auch nach oder während eines kaputten Updates, allerdings sollte man das Update danach noch einmal korrekt ganz durchlaufen lassen – das klappt dann meistens auch. Gegen zerstörte Datenbanken hilft die Snapshot-Funktion 🙂
Lösung:
Wenn die Appliance auf dem Upgrade-weg komplett zerschossen wurde, was passieren kann wenn ein Admin die VM wären des Prozesses im falschen Moment hart rebootet, hat mir die Anleitung zum manuellen Update sehr weitergeholfen. Danke @Martin Knaup (http://vaspects.blogspot.de/2013/05/workaround-for-vcenter-server-appliance.html). Das ist zwar unsupportet, aber in der Regel stressfrei und wesentlich sinnvoller als alles neu zu bauen – je nachdem wieviele Replikationsjobs, Backups, Regel und so weiter an dem vCenter dranhingen.