Aus den VMware Workstation 9.0.2 Release Notes:
Scrolling with a Lenovo ThinkPad UltraNav scroll button no longer requires excessive force.
Schade, dabei hatte dieser Kunde regelmäßig neue rote Trackpoint-Pömpel gekauft … 🙂
ugg.li Schnelle Hilfe für schnelle Admins
Nicht immer schön, aber effektiv. Schnelle Hilfe für schnelle Admins.
Aus den VMware Workstation 9.0.2 Release Notes:
Scrolling with a Lenovo ThinkPad UltraNav scroll button no longer requires excessive force.
Schade, dabei hatte dieser Kunde regelmäßig neue rote Trackpoint-Pömpel gekauft … 🙂
Manchmal konsolidieren Consolidation-Helper Snapshots von Backup-Programmen nicht korrekt. Wenn das nicht auffällt, landen bei jedem neuen Consolidation-Helper neue zusätzliche .vmdk-Dateien im Dateisystem:
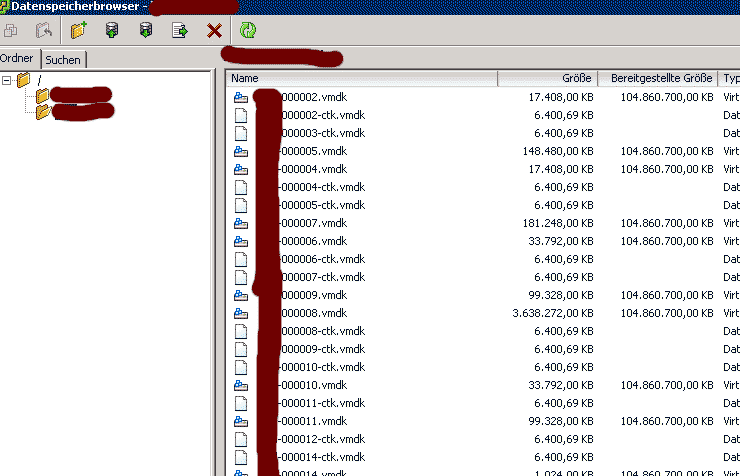
Diese fressen nach und nach den freien platz im Datastore auf und sind in der Snapshot-Ansicht nicht zu sehen:

Sobald man im Gast-Menü „Konsolidieren“ auswählt erscheint folgende Fehlermeldung im Log:
Zugriff auf die Datei <unspecified file> nicht möglich
![]() … oder deren Englischsprachiger pendant:
… oder deren Englischsprachiger pendant:
Unable to access file <unspecified filename> since it is locked
Die Ursache sind in der Regel VADP (vmware api for data protection) Backups, bei denen beim zurückrollen der Helpersnapshots ein Fehler aufgetreten ist.
Lösung
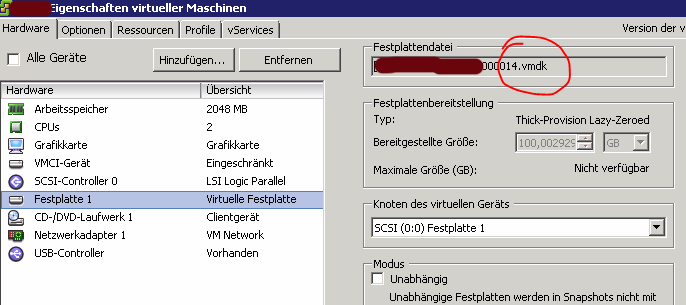 Öffnen einer SSH-Shell auf den Server, die diese Maschine registriert hat (verschieben ist vorher möglich) und wechseln in das Verzeichnis in dem die betreffende Maschine wohnt (z.B. /vmfs/volumes/4444444-4444444-4444-f4f4f4f4/meinemaschine/)
Öffnen einer SSH-Shell auf den Server, die diese Maschine registriert hat (verschieben ist vorher möglich) und wechseln in das Verzeichnis in dem die betreffende Maschine wohnt (z.B. /vmfs/volumes/4444444-4444444-4444-f4f4f4f4/meinemaschine/)vmkfstools -i meinemaschine-0000??.vmdk ./NEWdisk1.vmdk
Die „??“ entsprechen dem letzten Snapshot aus dem zweiten Punkt. Anstelle des aktuellen Pfades („./“) kann auch ein anderer Datastore zum Beipisle mit mehr Platz verwendet werden. Dieser vorgang dauert eine (ganze) Weile.
Das klappt alles sehr gut, solange es keinen I/O-Error im zugehörigen vmware.log gibt. Wenn das der Fall ist, ist die integrität mindestens einer .vmdk beschädigt; sofern die VM dann noch läuft klappt eigentlich nur noch ein Converter-Klon. Es sei denn jemand hat einen noch besseren Tipp für uns 🙂
Im Windows-Ereignisprotokoll tauchen diese Meldungen vom Typ „Warnung“ sehr oft auf:
Error in the RPC receive loop: RpcIn: Unable to send.
Im vmware.log der virtuellen Maschine finden sich ebensoviele Meldungen die so aussehen:
GuestRpc: Channel X, conflict: guest application toolbox-dnd tried to register, but it is still registered on channel Y
GuestRpc: Channel X reinitialized.
Ab und an crasht eventuell auch gerne mal die vmtoolsd.exe mit dem felgenden Fehler:
Access violation (0xC0000005)
Das ist ein Bug in den vmware Tools. Es gibt auch einen ausgewachsenen ESX(i) Patch dagegen: http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2036350 (direkter Download-Link). Das funktioniert natürlich auch und ist die saubere Lösung.
Instaliert wird ein VIB (nach dem hochladen in einen Datastore) generell mit:
C:Program Files (x86)VMwareVMware vSphere CLIbin> esxcli.exe -s SERVER -u root software vib install -v /vmfs/volumes/DATASTORENAME/VMware_locker_tools-light_5.1.0-0.9.914609.vib
Lösung: Schnelle Hilfe im laufenden Betrieb bringt dieser NICHT OFFIZIELLE Patch. Das Script wendet einfach die in dem KB-Artikel beschriebenen einstellungen auf die VMWare-Tools-Services an und startet diese neu. Kein Ausfall. Einfach das Script in der laufenden Windows-Maschien ausführen, fertig.
Download: vmware_patch_2036350 »
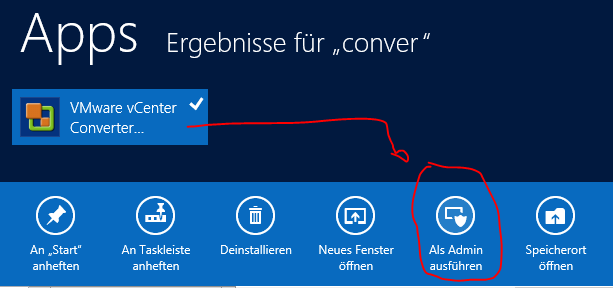
Einen unfreundlich aussehenden „unknown Error“ erhält man beim VMware Converter unter Windows 8, wenn man versucht eine Linux-Quellmaschine zu konvertieren. Der Fehler tritt direkt beim abschliessen des Auftrages auf.
Lösung: Den VMware converter aus dem Startbildschirm heraus als „Administrator“ ausführen.
Auf manchen vmware vSphere Hosts macht sich diese Fehlermeldung im gelben Informationsbereich bemerkbar und versetzt den Host auch noch in den fiesen be-Warndreieckten Warnstatus:

"Dieser Host verfügt momentan über keine Verwaltungsnetzwerkredundanz"
Die Meldung stammt von dem eifrigen Management-Agent des ESX Hosts und hat eigentlich einen guten Grund. Das Verwaltungsnetzwerk („Management Network“) sollte (dringend) mit mindestens zwei Netzwerkkarten angebunden sein, denn sonst könnte ein Gast mit viel Traffic (sofern im selben Netzwerk) das Management erheblich stören. In der wundervollen heilen vmware-Welt hat natürlich jeder Host mindestens zwei Netzwerkkarten für die Verwaltung, zwei oder mehr für vmotion, eine für den Cluster-Takt (und vielleicht FT) und dann noch mindestens vier für Gastsysteme – pro Netzwerk versteht sich. Da Hosts mit neun oder mehr Netzwerkkarten in der KMU-Welt mit unter zehn ESX-Hosts eher selten anzutreffen sind, erübrigt sich diese Warnung in vielen Fällen.
Sollte diese Meldung einmal trotz redundanter Anbindung auftauchen und nicht wieder freiwillig verschwinden, hilft oft einer dieser beiden Tricks:
Sollte das nicht helfen, tut aber auf jeden Fall die rohe Gewalt:
das.ignoreRedundantNetWarning True
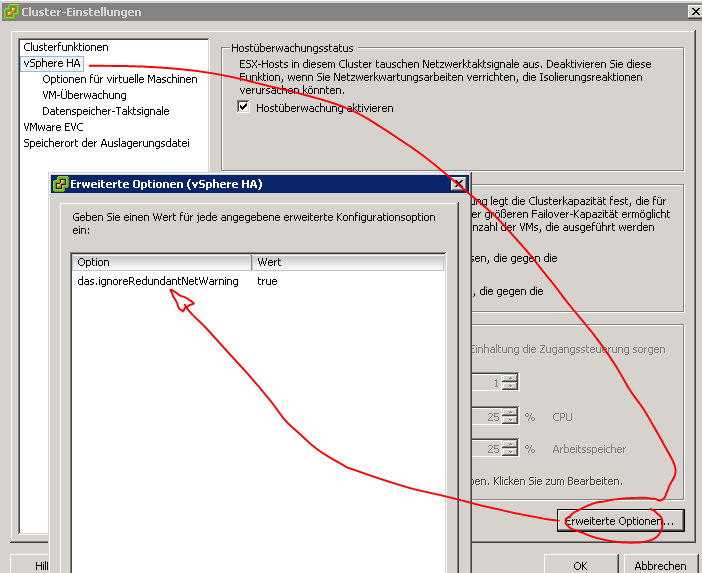 Dann ist die Warnung weg und erscheint auch bei keinem Host im ganzen Cluster wieder. jemals. auch nicht, wenn Sie recht hätte.
Dann ist die Warnung weg und erscheint auch bei keinem Host im ganzen Cluster wieder. jemals. auch nicht, wenn Sie recht hätte.