
Überalterte und/oder stark gestresste Batterien, auch in teuren Marken-USVs, neigen manchmal dazu, ihrem Arbeits-Ärger Luft zu machen. Gut das niemand in der Nähe stand 🙂
Nicht immer schön, aber effektiv. Schnelle Hilfe für schnelle Admins.
Überalterte und/oder stark gestresste Batterien, auch in teuren Marken-USVs, neigen manchmal dazu, ihrem Arbeits-Ärger Luft zu machen. Gut das niemand in der Nähe stand 🙂
WordPress erlaubt in der Standardkonfiguration leider bis heute noch keine Verwendung von SVG-Bildern in der Mediathek. Versucht man eine SVG-Datei hochzuladen erscheint der Fehler „<Name>konnte nicht hochgeladen werden. Du bist leider nicht berechtigt, diesen Dateityp hochzuladen.“
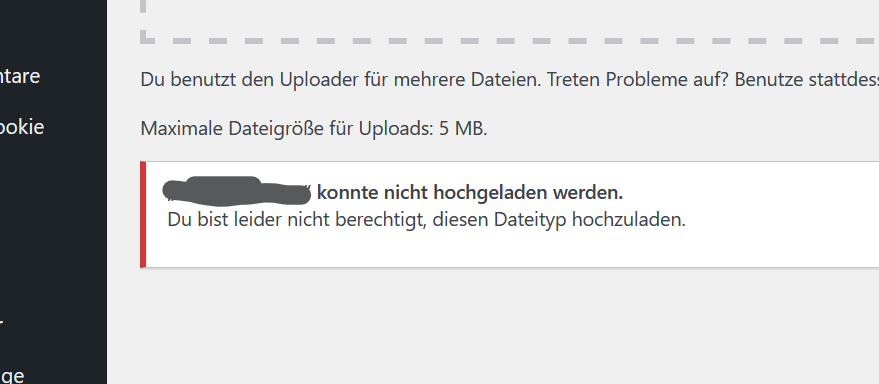
Das hat natürlich auch einen Grund: SVGs sind ja XML-Dateien mit potenziell ausführbarem JS-Inhalt. Die „falsche“ SVG Datei könnte, genau wie eine „falsche“ JS oder HTM* Datei möglicherweise Schaden anrichten.
Unverständlicherweise gibt es bis heute aber noch keine „offizielle“ Möglichkeit, SVGs in seinem eigenen privaten Blog zu erlauben.
In der functions.php des aktuell verwendeten Themes kann man den Filter einfach umgehen.
<?php
/* SVG erlauben - the old way */
function kb_svg ( $svg_mime ){
$svg_mime['svg'] = 'image/svg+xml';
return $svg_mime;
}
add_filter( 'upload_mimes', 'kb_svg' );
/* SVG erlauben - the new way (WP 4.7+) */
function kb_ignore_upload_ext($checked, $file, $filename, $mimes){
if(!$checked['type']){
$wp_filetype = wp_check_filetype( $filename, $mimes );
$ext = $wp_filetype['ext'];
$type = $wp_filetype['type'];
$proper_filename = $filename;
if($type && 0 === strpos($type, 'image/') && $ext !== 'svg'){
$ext = $type = false;
}
$checked = compact('ext','type','proper_filename');
}
return $checked;
}
add_filter('wp_check_filetype_and_ext', 'kb_ignore_upload_ext', 10, 4);
?>
Natürlich sollte das nicht so sein, ein Theme sollte nicht die Sicherheitsfunktion des WordPress-Systems verbiegen müssen. Leider ist das bisher der schnellste Weg für Admins um SVG-Grafiken zu erlauben.
Samba ist das Standard-Tool für Unix-basierte Betriebssysteme um mit Windows-Freigaben via SMB oder CIFS zu interagieren. Es ermöglicht unter Linux die Datei- und Druckfreigabe von Windows-Computern aus zu nutzen. Grundsätzlich verwendet Samba das SMB/CIFS-Protokoll für einen ziemlich sicheren, stabilen und zuverlässigen Datei-/Druckerfreigabezugriff.
Gestandene Admins nutzen Samba natürlich auswendig. Für alle anderen ist diese Schritt-für-Schritt Anleitung gedacht.
Wir möchten einen Samba-Share (eine Windows-Freigabe) permanent unter Linux verbinden, so dass diese auch nach einem Neustart zur Verfügung steht.
1. Das Debian-Paket cifs-utils auf dem System installieren:
sudo apt-get install cifs-utils2. Erstellen des Ziel-Verzeichnis zum Mounten der Freigabe
sudo mkdir /media/freigabe3. Credentials (Anmeldeinformationen) ablegen. Die Datei wird die unverschlüsselten Zugangsdaten enthalten und sollte daher aus Sicherheitsgründen mit einem Punkt (.) zu einer versteckten Datei gemacht werden. Es empfiehlt sich außerdem, diese im Home-Verzeichnis zu erstellen und mit entsprechend restriktiven Rechten zu versehen.
Datei anlegen …
vi /root/.smbcredentials… mit diesem Inhalt:
username=benutzername
password=passwortZum Beispiel:
username=AD.EXAMPLE.COM\t.musterfrau
password=Schlup2s3i4mu867psieDiese Datei dann speichern und idealerweise nur für root lesbar machen. Dadurch wird der Zugriff von allen Nicht-Root-Konten ausgeschlossen.
chown root:root /root/.smbcredentials
chmod 400 /root/.smbcredentials4. Testen. Mit dem folgenden Befehl kann man die Windows-Freigabe jetzt auf dem Linux-System bereitstellen
sudo mount -t cifs -o rw,vers=3.0,credentials=/root/.smbcredentials //SERVER.AD.EXAMPLE.COM/freigabe /media/freigabeDas jetzt manuell gemountete Dateisystem bleibt für dieses Sitzung erhalten. Nach einem Reboot ist /media/freigabe aber wieder leer.
5. Automount: Der Share kann nun zur /etc/fstab hinzugefügt werden. Dann wird die Remote-Freigabe beim Systemstart automatisch bereitgestellt.
sudo vi /etc/fstabAm Ende der Datei diese Zeile hinzufügen:
//SERVER.AD.EXAMPLE.COM/freigabe /media/freigabe cifs vers=3.0,credentials=/root/.smbcredentialsDatei dann speichern und schließen. Die Verbindung lässt sich nun auch ohne echten reboot testen:
sudo umount /media/freigabe
sudo systemctl daemon-reload
sudo mount -aEs gibt zahlreiche Dinge, die beim mounten schiefgehen könnten. Hilfreich ist bei der Fehlersuche immer die verbose Ausgabe von mount:
sudo mount -vvvv -t cifs -o rw,vers=3.0,credentials=/root/.smbcredentials //SERVER.AD.EXAMPLE.COM/freigabe /media/freigabeIch habe ein paar mal den Fehler „cifs_mount failed w/return code = -13“ gesucht. Der Fehler „-13“ bedeutet ausgeschrieben:
CIFS: Status code returned 0xc000006d STATUS_LOGON_FAILUREDas steht schlicht für Name/Kennwort falsch. Mal stimmt die Domäne nicht, mal das Kennwort, mal der Name. Ein spezieller Stolperstein ist hier auch gerne die Begrenzung auf 20 Zeichen lange Benutzernamen – ist der Name länger, schlägt die Anmeldugn auf jeden Fall fehl.

Oft sinnvoll, zum Beispiel für Server 2008R2 Upgrades 😂 (thx u/rat_blue)
Nach dem letzten Patchday am 16.1.2024 zeigt Edge beim starten nur noch ein weisses Fenster an, erzeugt eine irrsinnige CPU-Last und erzeugt im Eventlog Einträge die einen Appcrash Protokollieren.
Das „weisse leere Fenster“ gilt auch für Chrome, manchmal auch für Firefox (allerdings gibt’s da schon einen fix) und alles was „msedgewebview2“ als Webview-Element verwendet.
Betroffen ist Windows Server 2022 21H2.
Im Ereignisprotokoll findet sich dabei dieser Eintrag, der auf „bad_module_info“ verweist, aber keine weiteren Details bereithält:
Name der fehlerhaften Anwendung: bad_module_info, Version: 0.0.0.0, Zeitstempel: 0x00000000
Name des fehlerhaften Moduls: unknown, Version: 0.0.0.0, Zeitstempel: 0x00000000
Ausnahmecode: 0xc0000005
Fehleroffset: 0x00007ff704a393ae
ID des fehlerhaften Prozesses: 0x3810
Startzeit der fehlerhaften Anwendung: 0x01da4a1151de7b46
Pfad der fehlerhaften Anwendung: bad_module_info
Pfad des fehlerhaften Moduls: unknown
Berichtskennung: d6beaba6-a725-44a9-bd16-dba961694a0c
Vollständiger Name des fehlerhaften Pakets:
Anwendungs-ID, die relativ zum fehlerhaften Paket ist: (Einen leeren weissen Screenshot spare ich mir)
Das Update ASAP deinstallieren:
wusa /uninstall /kb:KB5034129… geht auch via DISM …
DISM /Online /Remove-Package /PackageName:Package_for_RollupFix~31bf3856ad364e35~amd64~~20348.2227.1.4… oder sogar per GUI…
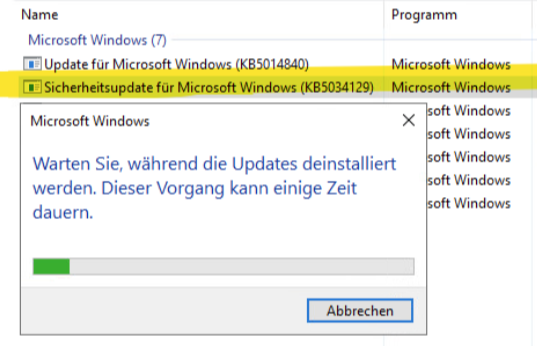
Nach dem Reboot läuft sofort wieder alles.